

Hard drives fade. DNA endures. Discover how scientists are turning life’s own code into the future of data storage and maybe human memory itself.
DNA is the building block of life. DNA stores all information about you. A human genome has around 750 MB of data. Nature surprisingly folds and coils this data into the nucleus of a tiny cell, which cannot be seen by the naked eye. This very compression advantage is why scientists are drawn to DNA for storing data.
Our big data explosion problem
We’re creating more data in a single year than in all of human history before it — and running out of places to keep it.
In today’s world, there’s a lot of noise about data privacy. Data is considered to be a precious asset. Companies bend over backwards with their terms of use and whatnot, just to peek at our data. If they can’t access our data, then they are just happy with our metadata. Creepy, but true. Scammers literally take lots of risks and pay lots of money just to buy our data from the dark web.
Now, all this makes it look like data is a prized commodity. Ah yes, it is. But what if I told you that, data is also our biggest byproduct. Shocked? Well, we defecate tons of data everyday – be it our insta reels, our TikTok videos, bank transactions, fitness app logs etc. Believe you me, all of this data just end up as 1s and 0s in our clouds, clogging up our data centers.
Right now, our global data storage is in zettabytes (1 billion TB). But it could reach yottabytes (1 trillion TB) by 2050. I’m not making this up. It’s what U.S. National Academies of Sciences predicted will happen.
Every byte we save costs metal, land, and power.
We are going to need lots of land just to build the data centers that can store all this data.
International Energy Agency Report (2024) claims that data centers globally consumed 415 TWh i.e., 1.5% of the electricity generated globally. Following this trend, electricity consumption of our data centers is expected to shockingly double by 2030.
What’s worse. The data centers need critical metals like cobalt, molybdenum and titanium. Mining these metals to meet our huge demand is costly and not at all environmentally friendly.
Data centers are notoriously known for generating large amounts of e-waste during each upgrade. Since the chips have a lot of materials mixed in it at a microscopic level, separating and recycling them is not an easy task. United Nations Global E-waste monitor 2024 report claims only less than 25% of the e-waste generated is actually recycled. The rest is processed informally or dumped into landfills.
The discovery of DNA and the idea of information
The molecule that only carried life’s code might soon hold our data.
A Swiss physician, Friedrich Miescher discovered DNA or deoxyribonucleic acid in 1869. At the time, he didn’t know his discovery was something remarkable. Instead, it was just a mysterious liquid extracted from the nucleus.
It was only in 1944, Oswald Avery, Colin MacLeod, and Maclyn McCarty proved that DNA was the molecule of heredity.
In 1952, Alfred Hershey and Martha Chase confirmed that DNA had genetic material upon observing the viruses that injected its DNA into the bacteria.
In 1953, using X-ray diffraction data (Rosalind Franklin’s Photo 51 and base pairing rules (Chargaff’s rules), James Watson and Francis Crick proposed the double helix structure of DNA.
Richard Feynman in 1959 speculated storing information at the molecular or atomic level in his lecture “There’s Plenty of Room at the Bottom”. It kind of planted a seed.
Decades later in 1988, an artist Joe Davis with the collaboration of Harvard Researchers encoded an image of a 35-bit runic symbol into the DNA of an E.coli bacterium. It was the first time someone had written a human artwork into a live DNA. It was revolutionary.
Fast-forwarding to 2012, Harvard Geneticists, George Church, Sri Kosuri and colleagues stored a 52000 word book, 11 images and a computer program into synthetic DNA. This was the first large scale digital to DNA encoding.
In 2025, a team led by Xiangyu Jiang and Jiankai Li from Southern University of Science and Technology, China published in Science Advances the first functional DNA “cassette tape” storage system. The idea is that strands of DNA can be arranged, read or overwritten just like a traditional cassette tape which can be read at a particular position and re-recorded.
In just a few decades, we have come a long way from discovering DNA to storing data in it.
How DNA data storage works
Every file you’ve ever created could, in theory, be rewritten into A, T, G, and C — the same alphabet that writes you.
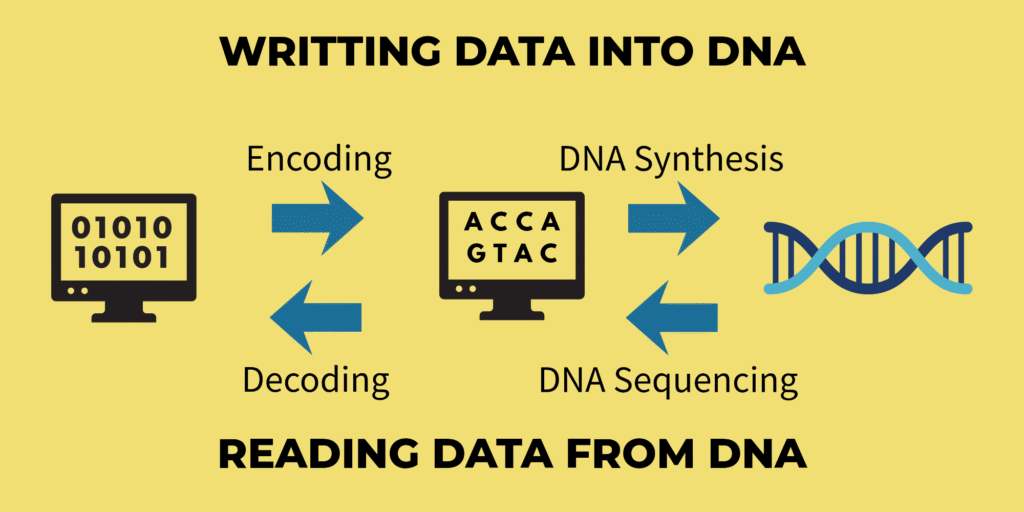
We all know all the data in the digital universe is stored as 0s and 1s.
So the first step to store this data into DNA is to convert these 0s and 1s into DNA letters i.e., A, T, G and C. This is the first step and it’s called Encoding.
Step 1: Encoding
Think of encoding as changing the 0s and 1s into DNA letters as follows
00 -> A
01-> T
10-> G
11-> C
So for example a binary code such as 01101100 will be encoded as TGCA in DNA code.
Step 2: DNA synthesis
Once the data is converted into DNA code, it is then physically built. This process is called DNA Synthesis. This is done using chemical or enzymatic reactions that link bases together in a precise sequence.
Now the data is synthesized to a small drop of DNA that is too small to be seen by the naked eye.
Step 3: Redundancy & error correction
DNA isn’t perfect. Reading and writing the DNA can sometimes create small damages to the DNA.
For example, imagine you are writing a big novel by hand. While writing it you might miss a few alphabets. And strangely, each time you read the novel some alphabets get smudged due to sweaty fingers.
Something similar happens to DNA while synthesis and sequencing. While synthesising errors can occur. While sequencing sometimes damages happen. Since DNA synthesis and sequencing is very complicated these kinds of things usually happen.
So to prevent data loss, scientists make multiple copies of each strand through a process called coverage and add error-correction codes.
Now even if small damages occur, the system can still rebuild the data.
Step 4: Storing the DNA
The next step is to store the DNA. Unlike flash drives, DNA isn’t too bulky. A tiny vial of DNA could hold huge amounts of data.
It is estimated a gram of DNA can theoretically hold 200 petabytes of data i.e., 200,000 TB of data.
If kept cool and dry, DNA can survive for thousands of years without any problems.
Step 5: DNA sequencing
Reading the data in DNA is known as DNA Sequencing.
It is done by reading As, Cs, Gs and Ts in the order it was created. A computer then converts these to binary codes, reconstructing the file.
For example a DNA code “TGCA” will be read and converted to binary as 01101100.
Advantages of DNA storage
A coffee mug of DNA could hold all the data on Earth.
- Unbelievable data density
Data density of DNA is theoretically about 200 petabytes per gram. A mid-sized data center can hold around 20 petabytes of data. Just imagine how many data centers we can get rid of with just a gram of DNA. - Longevity
Hard drives can survive only 5-10 years. Magnetic tapes can survive for 50 years. After that they need to be replaced. DNA, on the other hand, can survive for thousands of years. Scientists have successfully sequenced DNA of Woolly Mammoths over 10000 years old and Neanderthal DNA of over 40000 years old. Our data if stored in DNA could outlive our species. - No refrigeration
Data centers use large amounts of water, refrigerants and power for cooling purposes. Whereas DNA once stored dried and sealed, it simply exists without an issue. - Eco-friendly
Unlike hard drives that use rare metals, DNA is made from carbon, hydrogen, oxygen, nitrogen and phosphorus which make life itself. Switching just a fraction of data to DNA can drastically reduce e-waste.
Disadvantages of DNA data storage
Right now, storing a movie in DNA costs more than making the movie itself.
- Slow reading and writing speeds
Writing data in DNA is hundreds of millions of times slower than writing data to a hard drive. Similarly reading data from DNA is thousands of times slower than reading data from hard drive. These speeds are totally impractical in today’s world. - Extremely expensive
It is extremely expensive to write data into DNA. Current synthesis rate is around $3500 per megabyte of data as claimed by Wyss Institute. The price needs to drop by a million times if it needs to compete with hard drives and cloud storage. - Energy and resource cost for production
Storing DNA doesn’t require much energy. But producing it requires lots of energy, reagents and enzymes.
The road ahead
Companies like Microsoft and Catalog are racing to make DNA storage faster and cheaper — the next hard drive may be a molecule.
Many forward-thinking companies are already in the race to make DNA storage technology faster and cheaper.
Microsoft along with University of Washington have demonstrated a fully automated system to store and retrieve data from synthetic DNA.
CATALOG, a company founded by MIT researchers, is actively working on a way to make DNA storage cheaper.
Twist Bioscience Corporation, Illumina Inc. and Western Digital are also working with Microsoft to revolutionize DNA data storage.
There is also a lot of talk around the world when it comes to storing cold data. Cold data refers to information that isn’t regularly accessed. For example, old medical records, old transaction details, super classified intelligence archives, etc. These data once stored are not going to be accessed regularly. But if we are able to effectively store all our cold data in DNA, it could relieve a lot of data centers around the world.
Like the 1950s hard drives existed only in the lab, so is DNA technology today. It is costly and slow and needs scientists to write and read data on it. But in time everyday users are going to use it, write data in it and read data from it the way we use hard drives. Maybe DNA will be the next way we pass our knowledge and our history to the future generations.
The science sounds amazing. I would call it impractical maybe. But at $1,000 per MB, who’s paying for this? Until I can back up my photos in DNA without taking a loan, I’ll stick to Google Drive.
I think DNA storage is just some bulls**t companies have made up to raise money and keep investors.
Thank you for your comment. You are right about one thing. You might need a loan or may be loans depending on your credit score to backup.
But even the hard drive technology was costly back in the day. In 1956, a 15 MB, IBM 305 RAMAC weighing around 1 Ton, could be leased for $3200 per month(roughly $38000 in today’s money). Today we can’t imagine that kind of money for 15MB.
In the same way, companies are working on DNA data storage. May be by 2040-2050 we might be able to migrate our cold data to DNA and then years to come, we might be using it like hard drives of today.
Yes no one attest anything about the future. But what about this company CATALOG. I mean, they claimed they in 2019 that they would make DNA storing technology affordable in next 5-6 years. I’m not seeing any affordability as it is 2025.
Yes you are right. Catalog said in 2019 they would make DNA storage cheaper. They have actually made some really good progress actually. They have made a machine called Shannon that makes DNA writing faster and cheaper in the long run by using thousands of pre-made DNA fragments and mix them in different ways to represent data instead of printing each molecule. Obviously it’s not as cheap as backing data on your phone to cloud, but, it’s something.